
语义拒识介绍
语义拒识
1、背景介绍
在智能设备交互中,存在全双工连续对话(一次唤醒多轮对话),全双工连续对话有以下几个特点:
(1)一次唤醒情况下进行连续对话,这里唤醒包含通过唤醒词唤醒或是通过强相关指令唤醒;
(2)由于受环境因素和开放式对话影响,全双工对话需要区分接收的语音哪些需要后续处理,哪些需要拒识处理;
(3)开放式收音对连续多轮对话的对话管理要求更高,保证对话的连贯性。
目前市面上,将全双工分为两种模式:
(1)场景式全双工。这种主要针对领域场景打造的,它主要响应一些垂直领域的指令或场景,比如音乐场景,可以进行连续的播放音乐、暂停、切换下一首等指令交互。这种模式更倾向于垂直域能力的打造;
(2)半开放全双工。如我们市面上的小爱音箱、天猫精灵等都是此类交互模式,这种模式没有领域限制,既可以场景的执行,又可以进行闲聊问答,因此问答的灵活性会更高一些。但是对对话的管理要求比较严格,需要在连续对话过程中准确判断哪些语音可以参与问答。
场景式全双工由于基于垂直域进行构建,因此在进行拒识处理时有较为清晰的界限。但是对于半开放全双工,在拒识处理上难度较大,不能像人一样可以基于上文信息自动进行信息筛选。
2、query语义内容分析
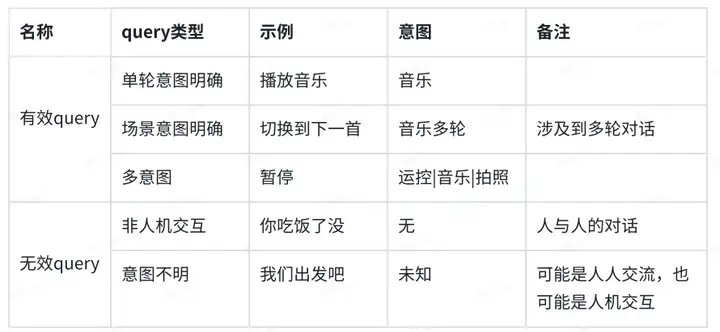
由上表我们可以看出,在全双工对话过程中,有效的query主要包含以下三种类型:
(1)单轮意图明确。即单轮对话就能够明确表达用户的意图;
(2)场景意图明确。可以根据当前垂域场景,确定query的所属意图。
(3)多意图。从文本上看有多个候选意图,由于缺乏场景信息,导致无法判断该意图属于哪个场景。
无效query主要包含以下两种类型:
(1)非人机交互。由于全双工连续对话,在对设备进行唤醒后,设备处于持续收音状态,这就会导致在收音的过程中会把周围不相关的声音进行语音识别,如果设备不能将无关人声进行过滤处理,就会影响正常的对话六合彩能,对用户交互产生较大干扰。
(2)意图不明。主要是乱序无意图(由于ASR错别字等导致的)、表达不完整、query意图模糊等导致的。
3、语义拒识难点
通过上面分析,非人机交互识别的难点主要有以下几点:
(1)信息不完备。我们在判断是否人机交互的时候需要通过多渠道信息进行综合判断(视觉、声音、文本);
(2)语音语调的变化。同一句话,由于语气、语调、语速等不同,产生不同的音频;
(3)模糊表达导致指向不明。
4、业界常见实现手段
4.1 人机对话上下文语义拒识方法(长虹专利)
url:https://pss-system.cponline.cnipa.gov.cn/retrieveList?prevPageTit=changgui
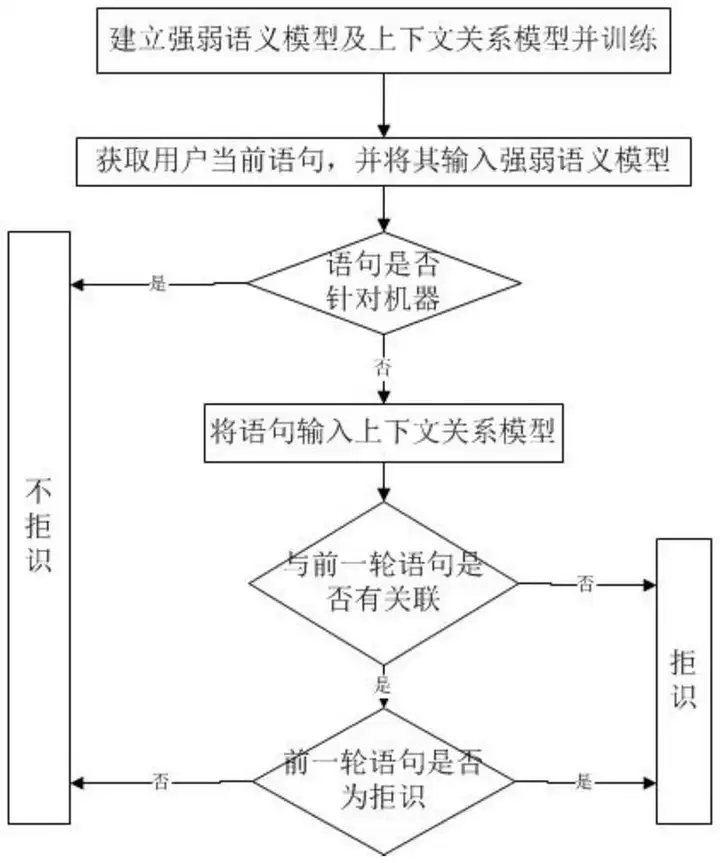
本文采用的拒识方法分为两步(如下流程图所示):(1)获取用户当前的query,进行强弱语义模型判断,判断语句是否针对机器人说出的;(2)构建上下文关系模型,上下文关系模型判断当前语句与前一轮语句是否有关联:若不相关,则当前语句为拒识;若相关且前一轮语句为拒识,则当前语句为拒识。
4.2 小爱全双工技术分享(小米)
url: https://www.sohu.com/a/408270107_500659
小爱同学的拒识方法演进过程如下图。
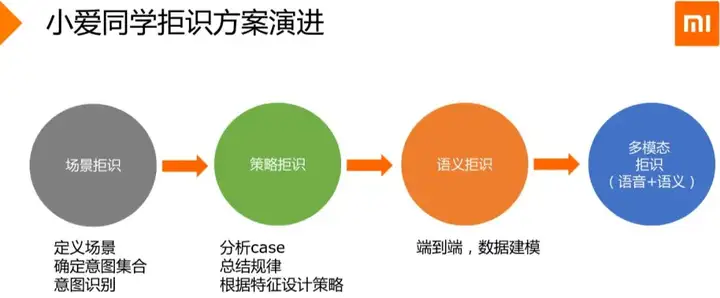
这里主要着重介绍拒识策略这一块内容:
- nonsense拒识
- 过长query拒识
- 长尾闲聊拒识
- 语速策略
注:需要根据实际对话场景和对话数据特征进行策略设计
小爱语义拒识也是基于当前query和历史query,建立二分类模型

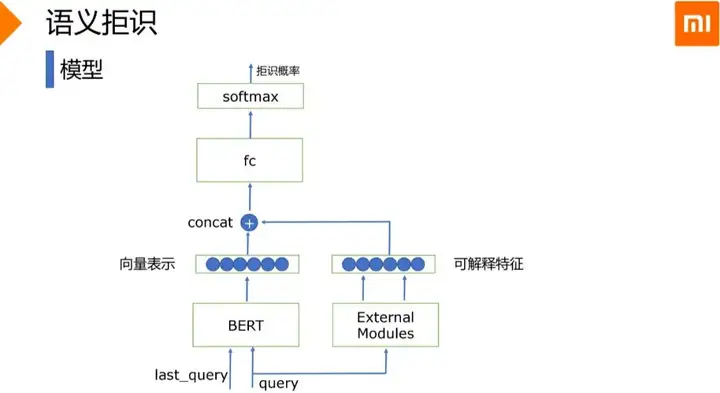
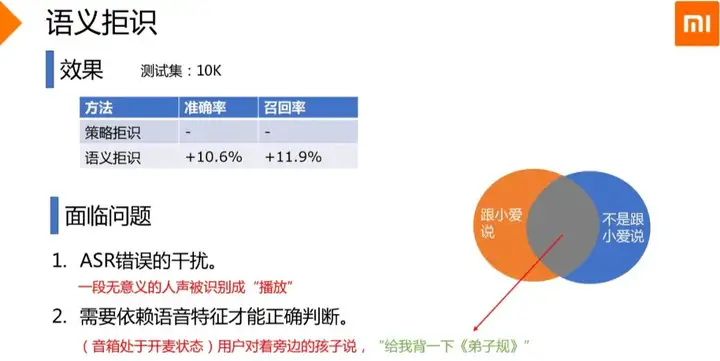
针对小爱语义拒识遇到的问题:
- 模糊地带的query容易误拒
- 纯语义拒识准确率偏低
小爱采用多模态语义拒识,融入更多其他特征来提升识别效果
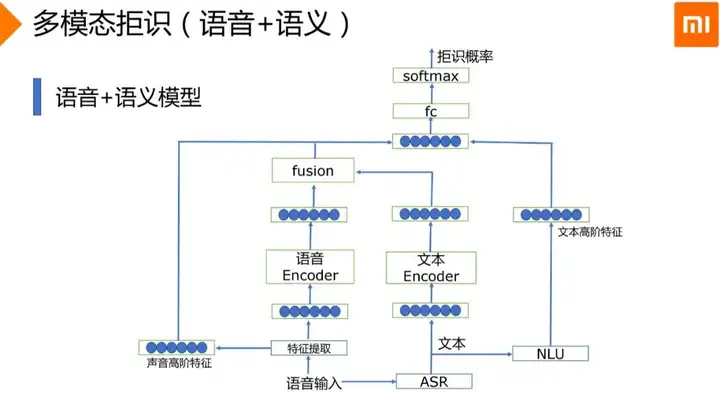
这里多模态模型融合了声音能提出的如音量、语速、信噪比等信息,同时还融合了NLU提取到的语义高阶特征进行融合处理,来提升多模态模型识别准确率。
4.3 思必驰全双工连续对话
url:https://www.sohu.com/a/361237304_463480
思必驰在拒识领域主要针对噪音信息进行拒识处理。思必驰拒识算法能够解决的很多噪声和无语义意义的问题,例如用户无意义的嗯啊声、背景噪声与闲聊声、纯音乐声、声音幅度小、各种笑声尖叫声,无厘头声音等。

transformer