
语音图鉴(一) - 走近语音交互
文章是介绍语音交互的一个基本流程,对于细节之处有一定程度的扩展,一适合些没有接触过语音的或者刚入行的开发人员可翻阅参考。语音的开发是一个细节众多,链路又长的过程,后面会出一系列文章从语音的各个维度归纳总结这些内容,最后形成知识闭环。
引言 作为语音的爱好者与从业者,在经过多年的项目积累,对语音开发的各个环节与架构,有了一些自己独特的思想与见解。语音交互的实现是一个很长的链路,任何一个环节做不好都会直接影响到最终的效果,所以这是一个精确度要求很高的领域。近些年汽车行业和语音技术的交叉,碰撞出了很多火花,车载语音已经是每一个车企在定义汽车时,不可或缺的一项功能。在经过了多年的车载语音开发工作后,梳理这部分内容的想法愈发强烈,所以希望通过这一系列文章,总结一下过往经验,形成完整的知识体系,供大家参考,欢迎各路专家交流指正。
一、语音交互介绍
1.概述
2023年随着ChatGpt的问世,越来越多的人对语音相关技术产生了浓厚的兴趣,相信很多人对这块或多或少有一些了解,语音交互就是一种人机交互方式,用户通过语音输入指令或提问,系统通过语音或文本方式回答用户问题。
典型的产品代表就是市场上形形色色的语音助手,比如天猫精灵、Siri、小爱同学等。近些年很多行业都在涉足语音交互这项技术,比如汽车、家具、教育、医疗、游戏等等,各行各业能跟智能搭边的都前赴后继加入语音系统的开发大战,语音交互逐渐成为了AI界的宠儿,同时人们对于语音交互的要求以及他的角色定位也不在满足于基本的查询功能。拿汽车行业来说,产品层面的设计已不单单是查看天气打开车窗这种基本Case,而是通过各种技术方案来提升交互体验,例如连续对话、可见即可说、主动感知交互、舒适的UI互动体验、闲聊对话、各种场景模式的定制开发等等等等。
随着各项技术的开源,做一个简易的语音助手也不再是什么难事,但是做一个流畅智能高效率情感化的语音交互软件是不容易的。语音交互的实现流程涉及知识点与模块众多,但它的主体交互流程是固定的。不同的是算法模型、对话管理、架构设计等一些细节上,也是这些设计的差异决定了一个语音产品的最终走向。此篇文章倾向于语音固定业务流程的介绍,后面我会陆续出一些文章,对各个细分模块进行详细的总结。
2.常见缩写释义
| 英文缩写 | 英文全称 | 中文解释 |
| ECNR | Echo Cancellation & Noise Reduction | 回声消除+降噪 |
| KWS | keyword spotting | 关键词发现 |
| ASR | Automatic Speech Recognition | 自动语音识别 |
| NLU | Natural Language Understanding | 自然语言理解 |
| DM | Dialog Manager | 对话管理 |
| NLG | Natural Language Generation | 自然语言生成 |
| TTS | Text To Speech | 文本转语音 |
| NLP | Natural Language Processing | 自然语言处理 |
三、语音交互流程
可能在大家的认知中,语音交互就是语音识别,其实不是的,识别只是智能语音众多环节中的一环,它要做的事情有很多很多。拆分开来,人机对话和人人对话的步骤环节完全一致,为了方便理解,我以一次语音交互举例说明:
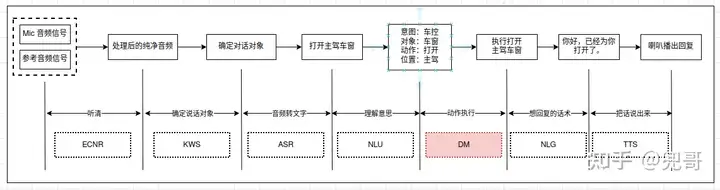
上述就是一次完整的语音交互:
"听清楚"->"确定说话对象"->"识别内容"->"理解意思"->"开始执行"->"想回复话术"->"说出来"
分别对应着:
"ECNR" ->"KWS"->"ASR"->"NLU"->"DM"->"NLG"->"TTS"
下面我对每个环节进行一下介绍:
ECNR
回声消除+降噪,语音在进行识别前,要对音频进行一些处理,从而拿到干净的音频提高识别的准确性。在车内语音通话场景中,受到各式各样形形色色的客观因素影响,除了我们知道的常规噪音外,还有就是"回声"。由于车内是个密闭空间,而且有多个扬声器,声波会在空间里发生折射,反射回来和其他声音混在一起,再被Mic采集。该模块的作用就是消除这个回声,和降低其他噪音。
那么回声是如何消除的呢?这里简单介绍下回声消除的原理,通常我们会向ECNR模块根据音区来增加几路参考信号,这些参考信号就是车内设备所发出的声音,EC模块通过对比音频来确定那些事回声哪些是原声,以此来消除这些回声。
ECNR只是我们语音前端处理的一部分,在进行系统开发前,我们会对mic布局、音频通路、参考信号的选取、声源定位等等进行测试调试,我们称之为turing,后面我会对这部分单独写篇文章进行介绍。
KWS
语音唤醒,在语音交互前,需要通过关键词检索的方式对语音系统进行唤醒,从而是语音系统切换为识别状态,也是一段语音对话的起点。道理很简单,一段对话的开始,要先确定对话的对象是谁,如果不是我,我就没有必要听对方的讲话内容。那通常来说对方的"姓名",也就是我们说的"唤醒词"。每个语音系统都有自己的唤醒词,像小鹏汽车的唤醒词“小P小P”,理想汽车语音唤醒词“理想同学”,蔚来汽车语音唤醒词“Hi,Nomi”。
KWS在检测到唤醒词音频后,会抛出唤醒事件,其中包括唤醒词类型,声源定位、置信度等信息。当然唤醒词不是唤醒语音系统的唯一方式,我总结归纳下了以下几种激活方式:
- 主动唤醒:即通过预先设定的唤醒词进行唤醒,唤醒后语音会给出唤醒应答,比如"你好呀"、"我来了"。
- OneShot:简称一语即达,与唤醒词唤醒不同的是,oneshot将唤醒和识别合二为一,比如"兜哥,今天天气怎么样"一句话连贯完成,语音系统不会反馈唤醒应答,直接做ASR及后续流程。
- 免唤醒词唤醒:这个叫法很多,有叫动态唤醒,有叫快捷唤醒,但效果一致,即不说唤醒词,直接说指令。通常这些免唤醒词会预设到配置文件中,比如:"下一首",会直接执行切换歌曲到下一首的操作。
- 被动触发:在某些特定场景满足后,语音交互会被动调起,一般借助车内传感器来完成这一操作。举例:车内有人吸烟,传感器检测到这一信息后,会发起语音交互,询问"是否打开车窗或开启空气净化"。从用户的角度看,用户并没有激活语音,语音在某些特定条件下主动发起交互,通常我们管这一操作叫"主动语音"或"主动运营"。
- 流程触发:根据语音交互流程设计,需要等待用户继续下发指令,则可以开启识别触发新一轮的交互,例如连续对话。
- 硬件触发:通过硬按键的方式对语音进行触发,比如手机里长按某个按键或者汽车上的方控语音按键,和主动唤醒类似。
ASR
自动语音识别技术,即将音频转换为文字。有些人会有疑问,同样是接收音频,唤醒和识别有什么不一样呢,不都是音频转文字吗?其实不然,"唤醒"要求的是快!,而识别要求的是准!这也就决定了二者实现上的不同。
第一个不同点:由于唤醒对实时性要求高,所以基本这部分的实现完全在端上处理,也就是本地处理,而不会放到云端处理。一是云端处理会有延迟影响时效性,二是安全隐私问题,因为唤醒的音频要一直录入,如果这些音频上传云端,你想想....(此处自己意会)。再说识别,识别由于要求准确性,通常会结合端和云一起处理,再将二者仲裁得到最准确的结果。
第二个不同点:二者的实现上也是不同的,唤醒更倾向于声音的相似度,不用等文字结果,就能快速响应即可。所以很多公司在做唤醒和识别时,是分别在两个不同的模型和引擎里来实现的。
其实现原理后面在ASR单独模块进行详细介绍。
NLU
他的作用是输入文本信息,输出这句话的真实意图。自然语言理解是整个语音链路中比较最难的一环,尤其在中文比较复杂的语言环境下。举几个例子:
peoplo : 我有点热。
voice : 空调温度降低了!用户没有提空调,但NLU要给出用户的最终意思。再说几个极端情况:
中国队大胜美国队,请问谁赢了;中国队大败美国队,这次谁赢了?
这几天天天天气不好。
用毒毒毒蛇会不会被毒死啊。这些就更难处理了。所以NLU的好坏会影响到谈话质量,你和一个听不懂你意思的机器在聊天,你还有兴趣吗?
NLU实现上涉及的技术广泛,比如文本预处理、词法分析、句法分析、语义理解、分词、文本分类、文本相似度处理、情感倾向分析、文本生成等等,且不局限于这些。通过一系列的算法处理,NLU会将语言文本转化为结构化信息,上层会通过解析结构化信息来实现对应的意图。结构化信息通常有三部分组成,"domain"、"intent"、"slots"。其中domain规定了意图的领域,initent规定了具体意图,slot则是传递了一些具体的细节参数。以"打开主驾车窗"为例,他的大致结构应该如下:
{
"domain": "CarControl",
"intent": "openWindow",
"slot": {
"position": "driver"
}
}DM
DM模块在整个语音系统有着最核心的地位,用于管理整个对话逻辑和状态,语音系统的所有业务逻辑的起点与枢纽。下图是DM在对话中所处的位置:
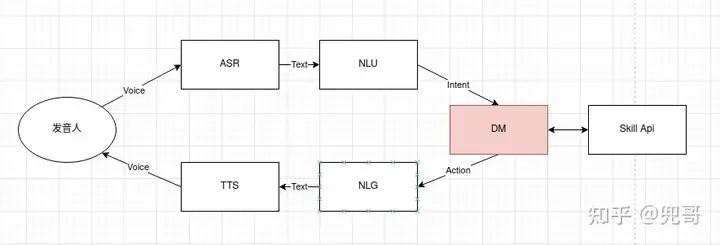
由图可见DM的中转作用,那么他究竟做了什么事情呢?我通过两个列子来说明他的作用:
案例一:
user : 导航到人民广场
voice: 找到以下结果,选第几个?
user : 今天天气怎么样?
voice:?这个例子很明显涉及到了跨域的问题,在导航的Context下,收到了查询天气的NLU结果,这个时候语音助手该如何处理?这就是DM需要做的事情。
案例二:
case 1:
user :帮我查下天气
voice:想查哪里的天气?
user :上海
voice:想查哪天的天气?
user :明天
voice:上海明天天气晴....
case 2:
user :帮我查下天气
(当前定位上海,默认当天天气)
voice:上海今天天气多云....
case 3:
user :帮我查下上海明天天气
voice:上海明天天气晴....这个案例的三种情况:
case1通过多轮对话来收集信息来完成任务。
case2通过第三方接口以及默认的规则来收集信息,只需要一轮对话就可以。
case3用户已将所有的消息都说出,所以一轮对话就搞定了。
在日常的语音使用中,人们大多数情况不太可能一句话把所有信息都涵盖。会通过各种途径方式,来收集信息,其中就包括多轮对话、三方接口查询、规则定义等。从而可见,DM主要就是一个收集信息的过程,也就是我们所说的"填槽"。
总结下来,DM接收了NLU的语义结果,结合历史对话信息以及上下文环境,维护语音系统的对话状态,并根据状态以及对话流的设计来驱动完成信息的收集。DM的具体的实现原理以及实现方案会在DM专项里详细介绍。
NLG
自然语言生成,他的作用是生成语音系统要回复的内容,将非语言格式的数据转换成人类可以理解的语言格式。NLG依赖于DM的输入,根据DM输入的参数信息,通过一系列逻辑判断,可以在预先设定的模板里找到对应的话术内容。
我目前接触到的NLG的实现方式,都是通过自定义的语法规则和格式形成配置文件,以配置文件查询的方式来实现NLG。在网上看到过很多用机器学习算法来分析数据并生成NLG结果,这个我目前尚无接触
说到这有人会有疑问,经常会听到人们说NLP,什么是NLP?NLP和NLG以及NLU是什么关系关系?
NLP的全名叫自然语言处理,他主要用于理解自然语言,同时能反馈自然语言。说到这其实很明显了,NLP有两个核心内容:NLU和NLG,所以他们的关系是包含关系,NLP是NLU和NLG的统称。
TTS
TTS是语音识别流程的最后一步,它将通过解析文本,将文本信息转换为音频,并输出到扬声器等设备上。总结来说TTS有两大部分内容,语音合成和语音播放,语音合成需要将文字合成音频,这部分技术水平的高低直接影响音频的质量和效果,语音播放的处理也至关重要,他处理方法得当会很大程度提升TTS的播出效果。
TTS不同于其他模块的是,他的应用场景更广,而且可以单独成立一个服务。在车载系统中,很多应用都有播放语音的需求,例如导航或者一些系统提示,这些播报是不掺杂语音业务的,所以TTS可以单独抽出作为公共服务模块。
三、总结
这篇文章是介绍语音交互的一个基本流程,对于细节之处有一定程度的扩展,一适合些没有接触过语音的或者刚入行的开发人员可翻阅参考。语音的开发是一个细节众多,链路又长的过程,后面会出一系列文章从语音的各个维度归纳总结这些内容,最后形成知识闭环。后面不仅会介绍语音的基础能力,像一些能力拓展“可见即可说”、“全双工语音对话”、“主动运营”、“语音输入法”等,还有架构方面的设计都会一一介绍。

兜哥