
一文让你更懂声纹识别:声纹,你的语音身份证
声纹: 一张 “语音身份证” 声纹是通过对语音中所蕴含的、能表征和标识说话人的语音特征,以及基于这些特征(参数)所建立的语音模型的总称。与人脸识别等行为特征相比,声纹识别因声音的特殊性更具生理特性。这种独特的特征主要由两个因素决定,第一个是每个人的发声腔不同,发声腔的尺寸,具体包括咽喉、鼻腔和口腔等,这些器官的形状、尺寸和位置决定了声带张力的大小和声音频率的范围。第二个决定声音特征的因素是发声器官被操纵的方式,发声器官包括唇、齿、舌、软腭及腭肌肉等,他们之间相互作用就会产生清晰的语音。人在学习说话的过程中,通过模拟周围不同人的说话方式,就会逐渐形成自己的声纹特征。因此,从理论上来说,声纹就像指纹一样,很少会有两个人具有相同的声纹特征。 声纹识别的过程主要分为三个阶段:训练阶段、注册阶段和验证阶段。在训练阶段,通过深度神经网络为输入的语音数据找到一个合适的向量表示;在注册阶段,对训练收敛的深度神经网络去掉最后一层分类层(一般会称为Softmax层),选取倒数第二层全连接层的输出向量作为该向量表示;在验证阶段,计算注册语音与其对应的测试语音之间的得分(如果得分高于一个预设定的阈值则接受,否则拒绝)。
声纹:一张 “ 语音身份证 ”
声纹,是对语音中所蕴含的、能表征和标识说话人的语音特征,以及基于这些特征(参数)所建立的语音模型的总称,而声纹识别是根据待识别语音的声纹特征识别该段语音所对应的说话人的过程。由于声音的特殊性,声纹识别与其他行为特征相比,又兼具生理特性。这种独特的特征主要由两个因素决定,第一个是每个人的发声腔不同,声腔的尺寸,具体包括咽喉、鼻腔和口腔等,这些器官的形状、尺寸和位置决定了声带张力的大小和声音频率的范围。第二个决定声音特征的因素是发声器官被操纵的方式,发声器官包括唇、齿、舌、软腭及腭肌肉等,他们之间相互作用就会产生清晰的语音。人在学习说话的过程中,通过模拟周围不同人的说话方式,就会逐渐形成自己的声纹特征。因此,从理论上来说,声纹就像指纹一样,很少会有两个人具有相同的声纹特征。
因此我们可以把声纹提取的特征或者说是“数字密码”,用来标识、解析、识别一个生物个体的唯一性,生物个体也可以是人类,或者动物。声纹提取的特征通常会被向量化(Embedding)为一个或多个数学向量,例如512维或1024维的向量,那么我们可以将这个向量,如同身份证上的18位数字一样,在某些场景下作为另外一种方式存在的“虚拟身份证”,我们可以给它起个有趣的名字——“语音身份证”。
声纹识别与语音识别的区别
声纹识别试图寻找的是区别每个人的个性特征,而语音识别则是侧重于对话者所表述的内容进行识别。简而言之,语音识别(Automatic Speech Recognition,ASR)关心说的什么,声纹识别(Voiceprint Recognition,VPR)关心谁说的。
根据实际场景需求的区别,在“2019中国声纹识别产业发展白皮书”中将声纹识别细分为如下几类。(1) 声纹确认即给定一个说话人的声纹模型和一段只含一名说话人的语音,判断该段语音是否是该说话人所说。 (2) 声纹辨认即给定一组候选说话人的声纹模型和一段语音,判断该段语音是哪个说话人所说。(3) 声纹检出即给定一个说话人的声纹模型和一些语音,判断目标说话人是否在给定的语音中出现。(4) 声纹追踪即给定一个说话人的声纹模型和一些语音,判断目标说话人是否在给定的语音中出现,若出现,则标示出对话语音中目标说话人所说的语音段的位置。
从另外一个维度,因为说话人语音天然蕴含着说话内容信息,根据声纹识别与待识别语音的文本内容的关系,声纹识别又可分为三类。(1) 文本无关即对于语音文本内容无任何要求,说话人的发音内容不会被预先限定,说话人只需要随意录制达到一定长度的语音即可。这种方法使用起来更加方便灵活,具有更好的推广性和适应性。(2) 文本相关即要求用户必须按照事先指定的文本内容进行发音。由于文本相关场景下,语音内容受到限定,整体随机性比文本无关场景下的小,所以一般来说其系统性能也会相对好很多。(3) 文本提示即从说话人的训练文本库中,随机提取若干词汇组合后提示用户发音。既对语音内容的发音范围进行了限定,又通过随机组合的方式,保留了语音内容的随机性,是文本无关与文本相关的一种结合。
声纹家族史
近些年来,声纹识别的技术发展迅速,经历了从i-vector(identity vector, i-vector)到d-vector(deep vector)再到x-vector经历了一系列的发展历程。传统的i-vector模型并不区分说话人空间和通道空间,而是将这两个空间合并起来形成一个总体变化空间(Total Variability Space,TVS),采用类似于主成分分析的因子分析方法,使用T矩阵将高维的高斯超向量进行降维并提取出能代表说话人信息的低维总体变化因子(i-vector),然后在低维的i-vector空间里应用线性判别模型(Linear Discriminant Analysis, LDA)来进行通道补偿,进而分离说话人信息和通道信息。如此可见,传统i-vector模型的本质就是一种线性降维模型。
首先我们需要做的就是将原始录音文件转换成声学特征,这里我们选择传统的声学特征梅尔频谱倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC),然后使用高斯混合模型GMM建模,因为从目标用户那里收集大量的录音数据非常困难,我们使用大量的非目标用户数据来训练一个GMM,这个GMM可以看作是对语音的表征,但是又由于它是从大量身份的混杂数据中训练而成,它又不具备表征具体身份的能力。因此我们需要基于目标用户的数据在这个混合GMM上进行参数的微调即可实现目标用户参数的估计,学术界基于此目标又提出了GMM-UBM模型,UBM(Universal Background Model, UBM)指通用背景模型。i-vector的计算是根据下面的公式所得:
M=m+Tω
其中:
M:说话人语言的超级向量;
m:说话人和信道不相干的超级向量;
ω:具有标准正态分布的随机向量,代表说话人和信道相关的向量,也即i-vector;
T:低秩矩阵,表示一个总体变化空间矩阵 ;
这里即i-vector, 在求解过程中,先要估计各阶统计量,然后总体子空间矩阵T的获得可以使用最大期望算法(Expectation- Maximization,EM)。这里得到的i-vector同时包含说话人speaker和信道channel的信息,可以使用LDA来减弱channel的影响。
当i-vector利用线性变换进行降维时,难于保留原始数据中的非线性特征。因此,科学界们想研究一种更好的非线性变换方法来将高维的高斯超向量降维得到说话人的低维总体变化因子。由此d-vector应运而生。
近年来,深度学习在语音识别领域中的成功应用鼓励着研究者将它运用到声纹识别中去。2015年以前的声纹识别论文中几乎看不到深度神经网络(Deep Neural Networks,DNN)的存在,如果涉及DNN,DNN也只是用于代替i-vector框架中的GMM模型去计算统计量或是提取瓶颈层特征(bottleneck,BN)等诸如此类的非本质性、非变革性的工作,直到谷歌公司提出d-vector概念。
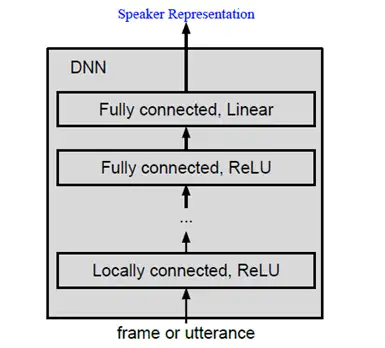
1. Linear是一种线性激活函数。
2. ReLU全称Rectified Linear Unit,是线性整流函数,一种神经网络激活函数。
声纹识别的过程主要分为以下三个阶段:
(1) 训练阶段
通过DNN为输入的语音数据找到一个合适的向量表示,希望能找到一个隐变量空间,可以训练出来对所有人的分类器,每个人都是这个隐变量空间的一个向量。具体做法是采用有监督的学习方式:输入训练集为语音数据和每条语音(Utterance)对应的说话人标签(Label),DNN的训练目标就是尽可能准确地给出输入语音的标签,即提高语音的分类准确率。
(2) 注册阶段
对应一个训练收敛的DNN我们去掉它的最后一层分类层(一般会称为Softmax层),选取倒数第二层全连接层(Fully Connected Layer,FC)的输出向量作为DNN对一条语音数据的向量表示,并把这个向量称为d-vector。此处得到的d-vector类似于传统方法中的i-vector,可以用作后面的分类、打分等操作。
将某个说话人提供的多段语音输入到第一阶段训练好的DNN模型中得到一系列d-vectors,将这些d-vectors做平均计算就得到了对应于该说话人的个性化模型(Speaker Model)。
(3) 验证阶段
声纹验证阶段的具体任务是计算注册语音与其对应的测试语音之间的得分(Score),如果得分高于一个预设定的阈值则接受,小于则拒绝。在这个步骤中,可能存在两种类型的错误:一是错误拒绝(False Reject,FR);二是错误接受(False Accept,FA)。当FR和FA相等时,这个共同的值我们称之为等错误率(Equal Error Rate, EER)。用打分函数用于计算两个向量之间的余弦距离。
我们将上述阶段整合得到了一个简单且全新的架构——端到端架构(End-To-End),在此架构中,我们用DNN来建模作为说话人语音的特征表示,并使用这个同样的DNN来做注册和验证工作,这套架构的最终得到接受和拒绝损失loss来训练整个网络。
X-vector是当前声纹识别领域最主流的基线模型框架,是基于时延神经网络(Time-Delay Neural Network ,TDNN)。假设整个结构简化为输入层、2个隐藏层、输出层为识别出B\D\G的音素。
TDNN来自1989年的论文“Phoneme recognition using time-delay neural networks”,A.Waibel, T. Hanazawa,G. Hinton,K. Shikano and K.J. Lang.“Phoneme recognition usingtime-delay neural networks,” in IEEE Transactions on Acoustics,Speech,and SignalProcessing,vol. 37,no.3,pp. 328-339,March 1989,doi: 10.1109/29.21701.
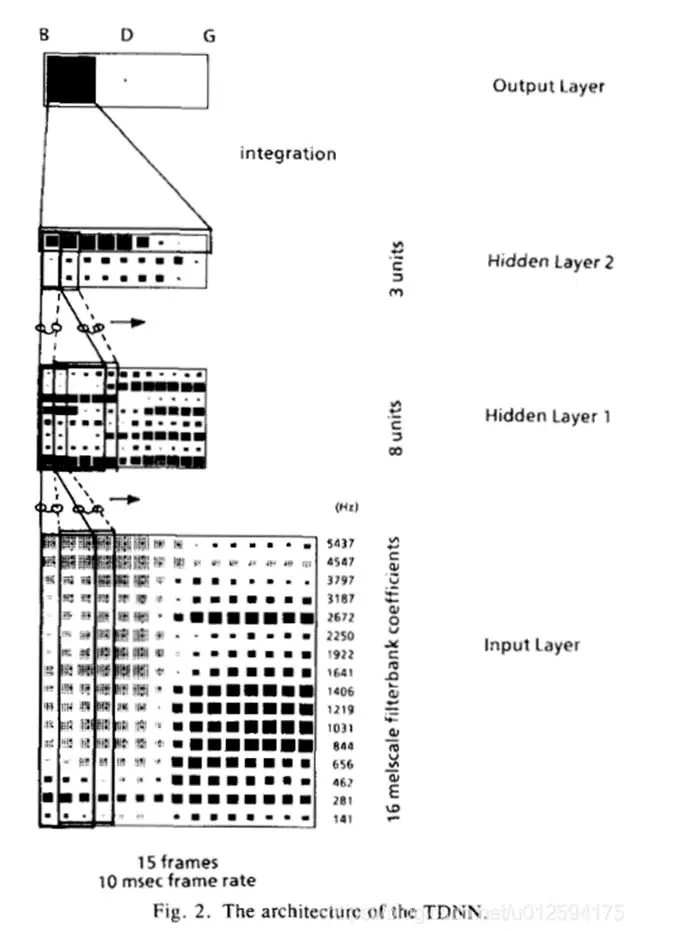
在输入层(Input layer),即连续的语音要输入到神经网络里,语音用一帧一帧来进行分段,每一帧的帧长10ms,如果用mel滤波器的16个特征表征(当然也可以用其他的特征提取算法),也就是每一帧就是图中输入端的一个竖形的矩形向量,代表t时刻的此帧的语音数据。
在隐藏层1(Hidden layer1)共有8个节点,当前时间t的节点(图中矩形图中第一个竖状的矩形向量)与输入层的t、t+1、t+2都有关联,延时为2,也就是隐藏层1的节点是由输入层的3个时间点的帧来计算出来的。时间向前滚动,在t+1时刻,也就是隐藏层1的第二个竖状矩形向量,就与输入层的t+1、t+2、t+3计算得来。隐藏层1的参数的数量=16×8×3=384(输入节点的16维特征向量,隐层1的8个节点数,关联了输入层的3帧)。
在隐藏层2(Hidden layer2)共有3个节点,隐藏层1 的延时为4,即当前时间t的节点与隐层1的t、t+1、t+2、t+3、t+4有关,隐藏层2的参数的数量= 8×3×5=120(隐层1的8个节点数,隐藏层2的3个节点数,关联了隐藏层1的5帧)。
在输出层(Output layer),隐藏层2的延时为8,到输出层的参数数量=3×3×9=81(隐藏层2的3个节点数,输出层的3个节点数,关联了隐藏层2的9帧)。
综上,合计参数数为585(即384+120+81=585)。
由此可以看出,延时网络TDNN对于语音的特征学习是非常适合的,因为语音与图像不同,天然就具备时序特点,TDNN网络随着时间的推进,可以从不同时序的语音数据中抓取更多与说话人身份密切相关的独有的表征。TDNN结构的优势在于,其相对于长短期记忆人工神经网络(Long Short-Term Memory ,LSTM)可以并行化训练,又相对于CNN\DNN增加了时序上下文信息。这在日常生活中我们可以体会,当我们接到一个陌生来电时,如果对方只说一句“喂”,我们可能愣住,一时猜不出是哪位朋友的声音。但当对方继续说了几句之后,我们的大脑快速反应,很容易辨识出来是哪个熟悉的声音。
除此之外,TDNN通过共享权值, 如下图所示,绿色线代表权值相同,红色线代表权值相同,蓝色线代表权值相同,以此类推。通过权值的共享,可以大大减少参数值,也就是训练和预测起来非常快,是一个非常轻量级的网络架构。
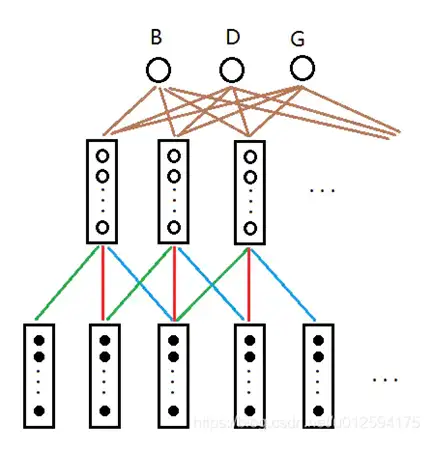
d-vector继承了TDNN的精髓如下,将不定长的语音通过加噪声和加混响进行数据扩充,然后经由深度神经网络映射成定长的向量,将映射之后的向量称为x-vector。在网络结构里,在池化层(Statistics Pooling)的下一步,第六层就可以输出声音所对应的512维Embedding向量表征。之后既可以通过Softmax进行分类,或者按概率形式线性判别分析(Probabilistic Linear Discriminant Analysis,PDLA)等来计算相似度得分。
面对未来的技术展望
随着2018年央行《移动金融基于声纹识别的安全应用技术规范》的颁布,以及2019年金融科技产品认证的出台,金融业继续稳居声纹识别产业的第一大民用领域。截至2020年下旬,约有30家银行机构采购了声纹识别技术产品,其中基于“动态声纹密码”的声纹登录场景首当其冲成为金融业第一大应用场景。值得思考的是,金融行业对安全性、用户隐私性要求很高,对技术的鲁棒性,规模可用性,安全性都提出了很高的要求,声纹技术首先在金融领域落地开花,也即意味着为以后在其他行业广泛地落地打下了坚实的技术基础。我们观察到以下的几个重要技术趋势。
(1) 基于电话信道、实时音频流的声纹识别
首先,当基于麦克风的文本相关或文本提示声纹识别较为成熟后,随后就是基于电话信道、实时音频流的声纹识别技术需要进一步攻关。基于电话信道的声纹识别目前还面临着许多挑战如:
- 噪声和采样率影响:电话信道噪声及环境噪声的叠加,电话采样率较专业收音设备采样率低,多以6kHz,8kHz为主,同时由于电话信道多为对话语音,角色分离的准确率不高,这几方面因素都对声纹识别准确率造成影响。
- 实时流处理难度高:电话信道的声纹识别使用场景大多数为实时对话,需处理实时流,需要从核心网设备或呼叫中心服务器同步语音流,并与元数据对应,实施难度大。
- 被动采集涉及隐私保护问题:基于电话信道的声纹识别可实现无感知注册及验证,但会涉及隐私保护问题。此外,被动采集声纹信息,音频质量不可控也是难点。
- 跨信道训练与预测:由于基于电信信道中文的大数据集的缺乏,模型的训练可能基于非电话信道数据,而模型的预测为电话信道数据,导致精度的下降。
(2) 超大规模声纹辨认性能
近些年,公安部正在规划将声纹识别技术纳入公共安全防治举措的方案,并开展声纹采集设备选型。各地公共安全领域相关部门也在加大声纹采集力度。与此同时,声纹数据库建设工作和建库规范也开始提上日程。但在类似公安的声纹库场景里,就属于典型的1:N声纹辨认,实验和实际项目应用中都发现,当N呈现上升时,EER和topN准确率、搜索效率、预测结果的响应速度等性能都会急剧下降。在N的数量达到万人规模时,是不是声纹识别的性能就几乎是不可用的?能否达到商用级别的要求?但像公共安全、金融保险的行业,声纹库的规模一定是在百万级或以上的。这目前是业界需要解决的难点。
(3) 多模态多任务联合识别
2020年初春,一场新型冠状病毒肺炎疫情如同一个黑天鹅效应,让整个世界范围、各个行业措手不及。疫情来临后,人脸识别的很多场景都遇到了麻烦,用户佩戴口罩,只露出眼眉等部位,人脸识别系统就无法识别出来。如果每一个通过闸机的用户都得摘掉口罩才能识别,又增加了感染的风险。疫情之下,促使了非接触、多模态技术的蓬勃发展。单个识别技术如人脸识别对于光照强弱、口罩遮挡、表情变化、尺度变化、设备采集角度等常见问题有局限性,精度无法达到某些场景下商业要求。且人脸识别广泛应用后,个人隐私数据被各类系统广泛采集,仅凭单一识别技术存在漏洞和安全风险,特别是涉及金融支付、用户认证等。
疫情影响下,在电梯、门禁、闸机、取款设备等多种场景下都提出了非接触需求,多模态技术融合后的产品形态将会明显提升用户使用体验,也就是在这些场景下,声纹+人脸联合进行识别成为重要趋势。
同时,从国际趋势上,由美国国家标准与技术研究所(National Institute of Standards and Technology,NIST)主办的说话人识别评估自1996年以来一直是最具代表性的说话人识别竞赛之一。来自世界各地的研究团队不断探索用于说话人识别的新算法和最新技术。
2019年 NIST SRE 包括两个独立的活动。
①对话电话语音对话电话语音(Conversational Telephone Speech,CTS)评价数据包括从 CMN2 数据集获得的含有对话的电话语音。CMN2 即 Call My Net2属于神经网络的训练或测试数据集名字。
②多媒体其评价数据包括语音技术视频标注( Video Annotation for Speech Technology,VAST)语料库中的音频和视频数据。
2019年NIST SRE的主任务为音视频(Audio-Visual)联合识别,新加坡国立大学基于此任务发表了最新成果《声纹系统采用x-vector模型:人脸系统采用ResNet/Insightface模型)。在此篇论文中,Audio-Visual的混合方案(Fusion : AV)的EER相比单独任务的EER等指标有明显下降。
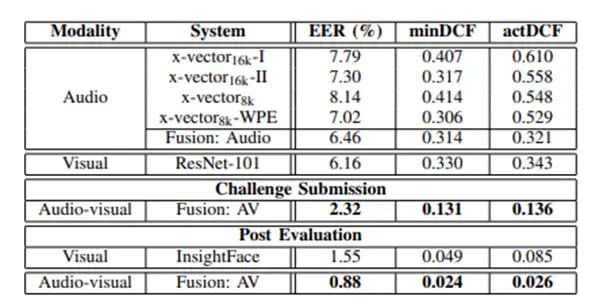
注:1. EER(等错误率,Equal Error Rate)2. min DCF(最小检测代价,Minimum Detection Cost Function)3. act DCF(实际的错误代价函数,Actual Detection Cost Function )
我们看到如果声纹识别和人脸识别单独执行、然后再用逻辑综合判别,无法充分利用关联的参数,当多个单任务的判别结果相悖时,例如声纹识别验证通过,但人脸识别验证失败,那该如何判别呢?采用多任务架构(Multi-task learning,MTL)用一个模型的参数共享来训练,输出出多个任务结果是一个可预见的解决之道。
除了声纹+人脸联合识别,声纹+语音联合识别,声纹+语音鉴伪联合识别,语种识别和说话人身份同时识别等多任务识别都属于学术界的热点,也是未来的重要方向。例如在语音识别和声纹识别任务中,语音中的很多特征是共性的,有相关性的,但也有各个任务相关的独有的特征,在多任务学习领域有多种结构,通过硬参数共享,软参数共享,引入对抗训练后的共享模型等方式去解决具体场景中的多模态、多任务的具体问题。
除以上三点趋势之外,对于短语音、重叠音的识别重点攻关;针对同一个语音的易变性,例如生理特征变化(年龄、病理)发音过程控制模式多样性、发音内容变化性在抗时变性能上进一步增强;进一步提高在跨信道场景下的鲁棒性;研究端到端识别技术的可用性及应用范围;研究无感知声纹,在自然语言对话场景中通过自然对话中的语音来作声纹确认;以及语音防攻击、语音鉴伪等都成了业界中的重点研究领域和技术趋势,在这里不一一展开。

语音之家-AI工匠学堂